TPU и зачем такие мощные видеодекодеры?
Тензорные процессоры (TPU) и нейронные процессоры (NPU) — это следующая ступень развития специализированных вычислительных устройств для задач искусственного интеллекта. Эти процессоры спроектированы с учётом специфических требований, предъявляемых алгоритмами машинного обучения и глубоких нейронных сетей.
TPU оптимизированы под работу с тензорами — многомерными массивами данных, которые составляют основу большинства современных моделей глубокого обучения. Основное преимущество TPU заключается в использовании матричных умножителей (MXU), которые с невероятной скоростью выполняют операции умножения матриц и векторов. Это делает их эффективным решением для обучения и инференса крупных моделей, таких как языковые модели или системы распознавания изображений, где требуется интенсивная обработка матричных вычислений.
С другой стороны, NPU, представляют собой более гибкое решение, сочетающее преимущества TPU с дополнительными возможностями для работы с различными типами нейронных сетей. NPU часто содержат специализированные блоки для выполнения операций свертки, активации и пулинга — все это важные составляющие сверточных нейронных сетей (CNN), используемых в задачах компьютерного зрения. Кроме того, NPU оптимизированы для работы с разной точностью данных, что позволяет находить баланс между производительностью и энергоэффективностью.
Ключевое отличие TPU и NPU от GPU в их способности более эффективно выполнять специализированные задачи нейронных сетей. Если GPU остаются универсальными вычислительными устройствами, способными обрабатывать широкий спектр параллельных вычислений, то TPU и NPU предлагают несравненную производительность и энергоэффективность в узконаправленных AI-задачах.
В случае SC7 HP75, помимо того что он TPU, а не привычный всем GPU, также выделяются его видеодекодеры, которые поддерживают кодеки H.264 и H.265 и могут обрабатывать до 2400 кадров в секунду на разрешении 1080p. Важность этого трудно переоценить для тех, кто работает с множеством видеопотоков одновременно: от систем безопасности с распознаванием лиц до анализов поведения в «умных» городах. Простая вычислительная мощность без способности обрабатывать большой объём видеопотока смысла имеет мало, так как иначе бы видеодекодеры стали бутылочным горлышком для работы всего ускорителя.

Характеристики SC7 HP75
Теперь перейдём к тому, что делает SC7 HP75 таким привлекательным в работе с нейросетями. Он построен на базе 24-ядерного процессора ARM A53 с частотой 2,3 ГГц, обеспечивающего вычислительную мощность до 169280 DMIPS. В вычислениях SC7 HP75 достигает до 96 TOPS в INT8, 48 TFLOPS в FP16/BF16 и до 6 TFLOPS в FP32. Это делает его подходящим для интенсивных AI-задач, включая обучение и инференс больших моделей. Теплопакет SC7 HP75 составляет скромные 75 ватт, так что с рассеиванием тепла справляет даже пассивное охлаждение, ARM-архитектура в этом плане не подвела, обеспечив высокую энергоэффективность. На борту 48 ГБ памяти LPDDR4x с пропускной способностью 205 ГБ/с, что обеспечивает высокую скорость работы с данными. Для подключения используется интерфейс PCIe Gen3 x16 с поддержкой PCIe Gen3 x8.
Особое внимание уделено видеообработке: декодирование видео H.264 и H.265 до 2400 кадров в секунду при разрешении 1080P, а также поддержка декодирования видео в разрешениях 8K, 4K, 1080P, 720P и ниже. Возможности кодирования видео включают 900 кадров в секунду на 1080P с поддержкой 4K и 1080P, что делает этот ускоритель оптимальным для работы с большим количеством видеопотоков в системах безопасности и «умных» городах. Кодирование изображений формата JPEG может достигать 1200 изображений в секунду при разрешении 1080P, с максимальным разрешением до 32768×32768 пикселей. Заявлена поддержка популярных AI-фреймворков, таких как TensorFlow, PyTorch, Caffe, MXNet и ONNX, а также операционных систем на основе ядра Linux.
ARM-архитектура: энергоэффективность и скорость
Основой SC7 HP75 служит 24-ядерный ARM A53 с частотой 2,3 ГГц. ARM-архитектура давно зарекомендовала себя как эффективное и энергосберегающее решение, и в случае SC7 HP75 это играет важную роль. Чем быстрее и эффективнее можно обрабатывать данные, тем больше задач можно выполнить за единицу времени, что особенно важно при работе с видео и инференсом в реальном времени.
Кроме того, ARM-архитектура позволяет SC7 HP75 превосходить таких конкурентов, как Nvidia T4, особенно в задачах, требующих быстрой реакции и минимальной задержки при анализе видеопотоков и распознавании объектов.
Сравнение с Nvidia T4
Когда речь заходит о производительности, SC7 HP75 однозначно бросает вызов Nvidia T4. В тестах на моделях глубокого обучения, таких как ResNet-50, SC7 HP75 демонстрирует хорошие результаты: 7082 операций в секунду против 6285 у T4. А в задачах, связанных с детекцией объектов, таких как SSD-Large, SC7 HP75 снова впереди с результатом 149 операций против 142 у конкурента, а также 214 у SC7 HP75 с BERT-LARGE и 213 у T4.
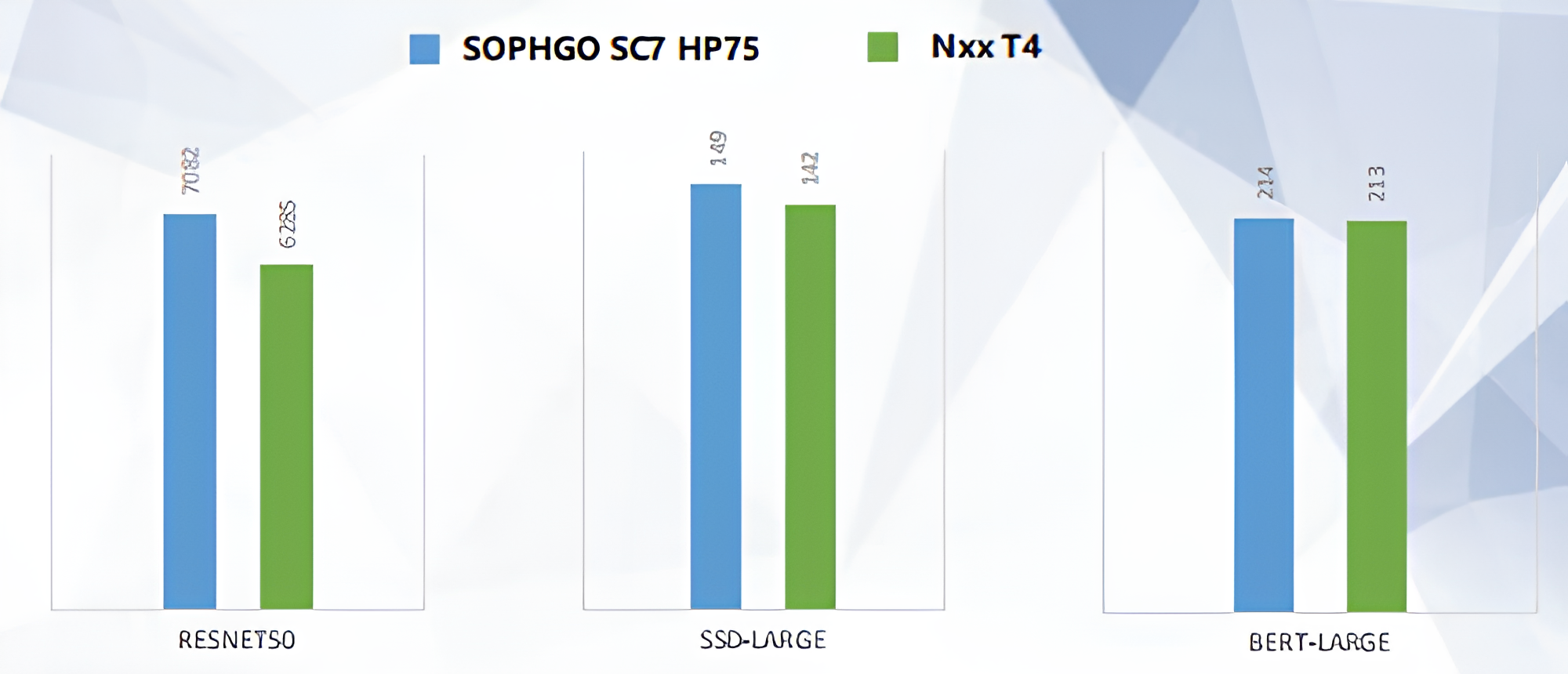
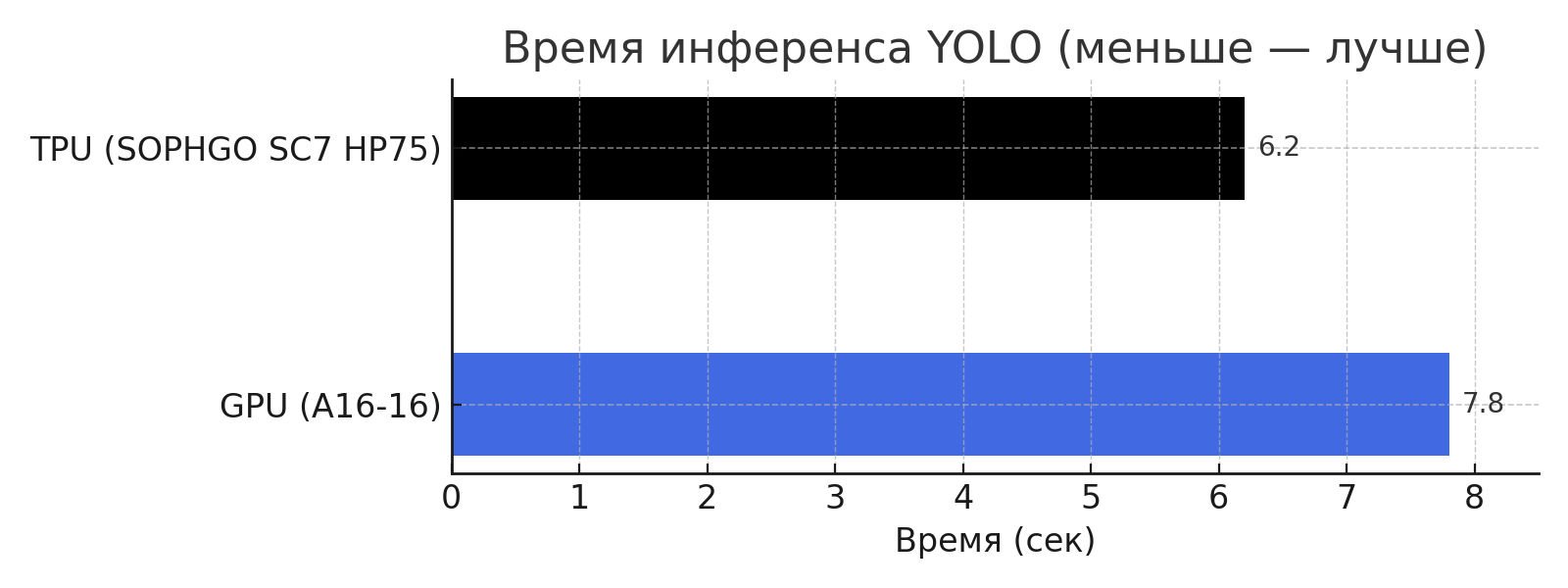
Результаты тестирования
Тестирование SOPHGO SC7 HP75 показало его высокую эффективность в задачах инференса нейросетей. В сравнении с сервером на базе GPU (nVidia A16-16) на модели YOLOv5s TPU-ускоритель справился с обработкой 30-секундного видео за 6,2 секунды, тогда как GPU потребовалось 7,8 секунды. Разница в детекции объектов оказалась минимальной (<0,04%), что подтверждает точность и стабильность работы TPU.
 В тесте на обработку аудиофайлов с использованием Whisper Medium на двух SOPHGO SC7+ (6 TPU) система показала следующий результат: 12 аудиофайлов продолжительностью 883 секунды каждый (общий объём 10 596 секунд) были обработаны за 1326 секунд, обеспечивая скорость 7,99 секунд аудио на секунду реального времени. Среднее время обработки одного запроса составило 661 секунду. Это доказывает, что TPU от SOPHGO способны эффективно справляться с задачами инференса в реальном времени, особенно в сценариях, связанных с потоковой обработкой данных, компьютерным зрением и ASR (автоматическим распознаванием речи).
В тесте на обработку аудиофайлов с использованием Whisper Medium на двух SOPHGO SC7+ (6 TPU) система показала следующий результат: 12 аудиофайлов продолжительностью 883 секунды каждый (общий объём 10 596 секунд) были обработаны за 1326 секунд, обеспечивая скорость 7,99 секунд аудио на секунду реального времени. Среднее время обработки одного запроса составило 661 секунду. Это доказывает, что TPU от SOPHGO способны эффективно справляться с задачами инференса в реальном времени, особенно в сценариях, связанных с потоковой обработкой данных, компьютерным зрением и ASR (автоматическим распознаванием речи).
Главное — это софт
Конечно, тесты и цифры — это прекрасно, но ведь железо без софта — всего лишь дорогостоящий кусок металла. И вот здесь начинаются настоящие вызовы. Не так важно, насколько хороша «начинка», если поддержка со стороны ПО и совместимость с популярными фреймворками оставляет желать лучшего. Ведь в конечном итоге всё сводится к тому, как эта мощь будет реализована на практике, в реальных задачах, а не в лабораторных тестах.
Nvidia десятилетиями шлифовала экосистему CUDA, вкладывая огромные ресурсы в разработку API, драйверов, инструментариев и документации, чтобы каждый разработчик мог с лёгкостью внедрить аппаратное ускорение в свою работу. Возьмите любой из популярных фреймворков для нейросетей — будь то TensorFlow, PyTorch или Caffe — и увидите, что большинство из них в первую очередь поддерживает именно NVIDIA.
SOPHGO, понимая важность поддержки ПО, сделала всё, чтобы SC7 HP75 был максимально совместим с ведущими фреймворками. Работаете с TensorFlow или PyTorch? Пожалуйста, подключайтесь без проблем. Caffe или MXNet? Опять же, никаких препятствий. Вдобавок, SophonSDK предлагает готовые инструменты для быстрой миграции существующих моделей на SC7 HP75. И это не просто красивые слова на бумаге — реально работающий софт, который избавит вас от головной боли при интеграции нового железа.
Заключение
SOPHGO SC7 HP75 — это не просто ещё один тензорный ускоритель. У компании получилось создать продукт, который не только обладает высокой вычислительной мощностью и способен потягаться с NVIDIA в бенчмарках, но и демонстрирует выдающуюся совместимость с популярными фреймворками, такими как TensorFlow, PyTorch, Caffe и MXNet. Поддержка этих инструментов, наряду с подробной документацией и SDK SophonSDK, делает интеграцию этого ускорителя в существующие инфраструктуры простой и удобной.
Если же вам уже сейчас нужно готовое решение для работы с нейросетями, наша платформа ITGLOBAL.COM — AI Cloud может полностью удовлетворить ваши потребности. В рамках платформы доступны не только SC7 HP75, но и такие ускорители, как L40S и H100 из прошлых обзоров. Для тех, кто хочет полностью своё решение, ITGLOBAL.COM также может выступить как системный интегратор, предоставив поддержку от поставки оборудования до проектирования и сопровождения всей инфраструктуры с нуля, в зависимости от ваших требований.
Источники:


